
Data Modelling with Apache Cassandra
This project focuses on building an Apache Cassandra database for Sparkify, a startup that offers music streaming services. Sparkify collects large amounts of user activity and song data, and the analytics team wants to query this data to better understand user behaviour, specifically around song preferences. The goal is to create an ETL pipeline to preprocess raw event data stored in multiple CSV files, consolidate it, and design and implement a Cassandra data model to support queries on the song play data.
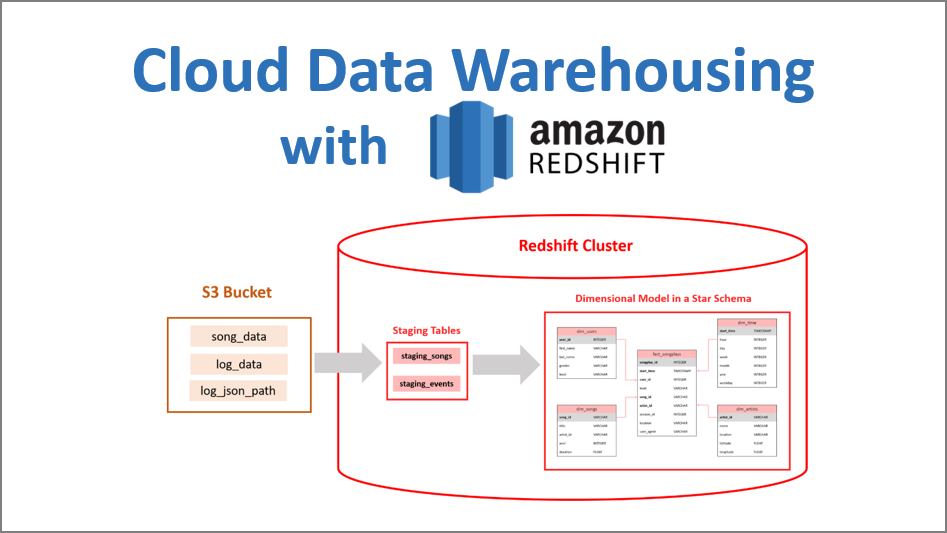
Cloud Data Warehousing with AWS Redshift
The project implements a scalable cloud solution for Sparkify's analytics team to gain insights from their user and song data. The goal is to build an ETL pipeline that extracts data from AWS S3 staging area, loads it into staging tables in a database hosted on Amazon Redshift cluster, and transforms it into a dimensional model with fact and dimension tables in a star schema that allows for efficient querying to answer business questions such as popular songs, user listening patterns, and peak activity times.

Centauri Alpha's Retail Data Consulting Project
- dbt
- Apache Airflow
- GCP BigQuery
- Fivetran
- Cloud Composer
- ELT
- Data Warehousing
- Power BI
- pandas
- Statistical Analysis
- Retail
- Customer Retention
- Business Strategy
- Boost Sales
- Data Analytics
- Data Engineering
- SQL
- Python
A data consulting project that I implemented for a retail business client
during my employment at Centauri Alpha.
The full experience includes:
• Ingested data from various sources to GCP BigQuery via Fivetran,
transformed data into medallion architecture through SQL models with dbt,
and orchestrated end-to-end data pipelines with Apache Airflow on Google Cloud Composer.
• Refactoring SQL code for existing dbt models to improve modularity, simplicity, accuracy,
maintainability, and readability.
• Collaborating with data engineers and analysts to meet project-specific reporting needs by defining
additional metrics in semantic layer, making them accessible to integrated BI tools.
• Analysing online sales data from the data warehouse using SQL queries and Python pandas to
identify key customer behaviour factor(s) influencing the client's total online sales. Utilising Spearman’s Rank
Correlation and Hypothesis Tests to analyse correlations.
• Performing customer retention analysis employing statistical methods such as Bayes’ Theorem and Confidence
Interval for Binomial Proportion, determining that 11% of products lead to high customer churn risk.
• Developing and evaluating a business strategy based on the retention analysis, projecting a potential 10.6%
increase in total sales revenue and the retention of an additional 6.2% of customers upon implementation.
• Presenting progress to stakeholders in weekly meetings, delivering data insights through visualizations with
Power BI.